This page was generated from docs/notebooks/01_getting_started.ipynb.
Getting Started with scHopfield
Network Inference
scHopfield infers gene regulatory networks (GRNs) from RNA velocity data using gradient descent optimization.
Theory
The Hopfield network dynamics are:
Where RNA velocity approximates \(dx/dt\). By fitting W (interactions) and I (biases) to minimize the difference between observed and predicted velocity, we infer the GRN structure.
Basic Usage
Preprocessing
Sigmoid Function Fitting
scHopfield uses sigmoid activation functions to model gene expression:
Where:
\(\theta\) is the threshold parameter
\(\alpha\) is the amplitude (typically 1)
\(\beta\) is the exponent (steepness)
offset is a baseline value
Fitting Process
The fit_all_sigmoids() function fits these parameters to each gene’s expression distribution:
scHopfield models gene regulatory networks (GRNs) as continuous Hopfield
networks, where gene expression dynamics follow:
W: Interaction matrix encoding gene-gene regulatory relationships
σ(x): Sigmoid activation function fitted to expression data
γ: Degradation rates (mRNA decay)
I: Bias vector representing external inputs / basal expression
This notebook walks through the full setup: data loading, sigmoid fitting,
network inference (with and without a scaffold), and saving/loading the model.
1.1 Setup & Imports
[1]:
import numpy as np
import scanpy as sc
import scHopfield as sch
import matplotlib.pyplot as plt
# Analysis parameters (update for your dataset)
DATA_PATH = './scratch/Data/'
DATASET_FILE = 'hematopoiesis.h5ad'
CLUSTER_KEY = 'cell_type'
VELOCITY_KEY = 'velocity_alpha_minus_gamma_s'
SPLICED_KEY = 'M_t'
DEGRADATION_KEY = 'gamma'
DYNAMIC_GENES_KEY = 'use_for_dynamics'
CELL_TYPE_ORDER = ['Meg', 'Ery', 'MEP-like', 'HSC', 'GMP-like', 'Mon', 'Bas', 'Neu']
# Network inference hyper-parameters
N_EPOCHS = 1000
BATCH_SIZE = 128
W_THRESHOLD = 1e-12
SCAFFOLD_REGULARIZATION = 1e-2
DEVICE = 'cuda' # or 'cpu'
/home/bernaljp/miniconda3/envs/SCH/lib/python3.11/site-packages/louvain/__init__.py:54: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import get_distribution, DistributionNotFound
1.2 Data Loading
The hematopoiesis dataset can be loaded from two sources:
Option |
Command |
Notes |
|---|---|---|
Local file |
|
Fastest; requires the file on disk |
dynamo |
|
Downloads on first use; |
The cell below tries the local file first and falls back to dynamo automatically.
[2]:
from fileinput import filename
import os
print("Loading data...")
_local_path = DATA_PATH + DATASET_FILE
if os.path.exists(_local_path):
print(f" Source: local file ({_local_path})")
adata = sc.read_h5ad(_local_path)
else:
# Requires: pip install dynamo-release
print(" Local file not found – downloading from dynamo (pip install dynamo-release)...")
import dynamo as dyn
adata = dyn.sample_data.hematopoiesis(filename=_local_path)
# Optionally cache locally to skip the download next time:
# os.makedirs(DATA_PATH, exist_ok=True)
# adata.write_h5ad(_local_path)
print(f" Loaded: {adata.n_obs} cells × {adata.n_vars} genes")
print(adata)
Loading data...
Loaded: 1947 cells × 1956 genes
AnnData object with n_obs × n_vars = 1947 × 1956
obs: 'batch', 'time', 'cell_type', 'nGenes', 'nCounts', 'pMito', 'pass_basic_filter', 'new_Size_Factor', 'initial_new_cell_size', 'total_Size_Factor', 'initial_total_cell_size', 'spliced_Size_Factor', 'initial_spliced_cell_size', 'unspliced_Size_Factor', 'initial_unspliced_cell_size', 'Size_Factor', 'initial_cell_size', 'ntr', 'cell_cycle_phase', 'leiden', 'control_point_pca', 'inlier_prob_pca', 'obs_vf_angle_pca', 'pca_ddhodge_div', 'pca_ddhodge_potential', 'acceleration_pca', 'curvature_pca', 'n_counts', 'mt_frac', 'jacobian_det_pca', 'manual_selection', 'divergence_pca', 'curv_leiden', 'curv_louvain', 'SPI1->GATA1_jacobian', 'jacobian', 'umap_ori_leiden', 'umap_ori_louvain', 'umap_ddhodge_div', 'umap_ddhodge_potential', 'curl_umap', 'divergence_umap', 'acceleration_umap', 'control_point_umap_ori', 'inlier_prob_umap_ori', 'obs_vf_angle_umap_ori', 'curvature_umap_ori'
var: 'gene_name', 'gene_id', 'nCells', 'nCounts', 'pass_basic_filter', 'use_for_pca', 'frac', 'ntr', 'time_3_alpha', 'time_3_beta', 'time_3_gamma', 'time_3_half_life', 'time_3_alpha_b', 'time_3_alpha_r2', 'time_3_gamma_b', 'time_3_gamma_r2', 'time_3_gamma_logLL', 'time_3_delta_b', 'time_3_delta_r2', 'time_3_bs', 'time_3_bf', 'time_3_uu0', 'time_3_ul0', 'time_3_su0', 'time_3_sl0', 'time_3_U0', 'time_3_S0', 'time_3_total0', 'time_3_beta_k', 'time_3_gamma_k', 'time_5_alpha', 'time_5_beta', 'time_5_gamma', 'time_5_half_life', 'time_5_alpha_b', 'time_5_alpha_r2', 'time_5_gamma_b', 'time_5_gamma_r2', 'time_5_gamma_logLL', 'time_5_bs', 'time_5_bf', 'time_5_uu0', 'time_5_ul0', 'time_5_su0', 'time_5_sl0', 'time_5_U0', 'time_5_S0', 'time_5_total0', 'time_5_beta_k', 'time_5_gamma_k', 'use_for_dynamics', 'gamma', 'gamma_r2', 'use_for_transition', 'gamma_k', 'gamma_b'
uns: 'PCs', 'VecFld_pca', 'VecFld_umap', 'X_umap_neighbors', 'cell_phase_genes', 'cell_type_colors', 'dynamics', 'explained_variance_ratio_', 'feature_selection', 'grid_velocity_pca', 'grid_velocity_umap', 'grid_velocity_umap_ori_perturbation', 'grid_velocity_umap_test', 'jacobian_pca', 'leiden', 'neighbors', 'pca_mean', 'pp', 'response'
obsm: 'X', 'X_pca', 'X_pca_SparseVFC', 'X_umap', 'X_umap_SparseVFC', 'X_umap_ori_perturbation', 'X_umap_test', 'acceleration_pca', 'acceleration_umap', 'cell_cycle_scores', 'curvature_pca', 'curvature_umap', 'j_delta_x_perturbation', 'velocity_pca', 'velocity_pca_SparseVFC', 'velocity_umap', 'velocity_umap_SparseVFC', 'velocity_umap_ori_perturbation', 'velocity_umap_test'
layers: 'M_n', 'M_nn', 'M_t', 'M_tn', 'M_tt', 'X_new', 'X_total', 'velocity_alpha_minus_gamma_s'
obsp: 'X_umap_connectivities', 'X_umap_distances', 'connectivities', 'cosine_transition_matrix', 'distances', 'fp_transition_rate', 'moments_con', 'pca_ddhodge', 'perturbation_transition_matrix', 'umap_ddhodge'
1.3 Preprocessing
Remove genes with NaN velocities by subsetting adata, then identify the
dynamic genes that will be passed to the model.
[3]:
# Remove genes that have any NaN velocity entry (hematopoiesis dataset)
print("Removing genes with NaN velocities...")
velocity_layer = adata.layers[VELOCITY_KEY]
if hasattr(velocity_layer, 'toarray'):
velocity_layer = velocity_layer.toarray()
bad_gene_idx = np.unique(np.where(np.isnan(velocity_layer))[1])
keep_mask = np.ones(adata.n_vars, dtype=bool)
keep_mask[bad_gene_idx] = False
adata = adata[:, keep_mask].copy()
print(f" After filtering: {adata.n_obs} cells × {adata.n_vars} genes")
# Boolean mask of dynamic genes used for modelling
genes_to_use = adata.var[DYNAMIC_GENES_KEY].values
n_genes = genes_to_use.sum()
print(f" Dynamic genes for modelling: {n_genes}")
Removing genes with NaN velocities...
After filtering: 1947 cells × 1728 genes
Dynamic genes for modelling: 1728
1.4 Sigmoid Fitting
Fit a sigmoid function to each gene’s expression distribution.
The fitted parameters are stored in adata.var.
[4]:
sch.pp.fit_all_sigmoids(
adata,
spliced_key=SPLICED_KEY,
genes=adata.var[DYNAMIC_GENES_KEY].values
)
sch.pp.compute_sigmoid(adata, spliced_key=SPLICED_KEY, copy=False)
print("Sigmoid fitting complete.")
print(adata)
/home/bernaljp/packages/scHopfield/scHopfield/_utils/math.py:93: RuntimeWarning: divide by zero encountered in divide
ty = np.log(y / (1 - y))
/home/bernaljp/packages/scHopfield/scHopfield/_utils/math.py:93: RuntimeWarning: divide by zero encountered in log
ty = np.log(y / (1 - y))
Sigmoid fitting complete.
AnnData object with n_obs × n_vars = 1947 × 1728
obs: 'batch', 'time', 'cell_type', 'nGenes', 'nCounts', 'pMito', 'pass_basic_filter', 'new_Size_Factor', 'initial_new_cell_size', 'total_Size_Factor', 'initial_total_cell_size', 'spliced_Size_Factor', 'initial_spliced_cell_size', 'unspliced_Size_Factor', 'initial_unspliced_cell_size', 'Size_Factor', 'initial_cell_size', 'ntr', 'cell_cycle_phase', 'leiden', 'control_point_pca', 'inlier_prob_pca', 'obs_vf_angle_pca', 'pca_ddhodge_div', 'pca_ddhodge_potential', 'acceleration_pca', 'curvature_pca', 'n_counts', 'mt_frac', 'jacobian_det_pca', 'manual_selection', 'divergence_pca', 'curv_leiden', 'curv_louvain', 'SPI1->GATA1_jacobian', 'jacobian', 'umap_ori_leiden', 'umap_ori_louvain', 'umap_ddhodge_div', 'umap_ddhodge_potential', 'curl_umap', 'divergence_umap', 'acceleration_umap', 'control_point_umap_ori', 'inlier_prob_umap_ori', 'obs_vf_angle_umap_ori', 'curvature_umap_ori'
var: 'gene_name', 'gene_id', 'nCells', 'nCounts', 'pass_basic_filter', 'use_for_pca', 'frac', 'ntr', 'time_3_alpha', 'time_3_beta', 'time_3_gamma', 'time_3_half_life', 'time_3_alpha_b', 'time_3_alpha_r2', 'time_3_gamma_b', 'time_3_gamma_r2', 'time_3_gamma_logLL', 'time_3_delta_b', 'time_3_delta_r2', 'time_3_bs', 'time_3_bf', 'time_3_uu0', 'time_3_ul0', 'time_3_su0', 'time_3_sl0', 'time_3_U0', 'time_3_S0', 'time_3_total0', 'time_3_beta_k', 'time_3_gamma_k', 'time_5_alpha', 'time_5_beta', 'time_5_gamma', 'time_5_half_life', 'time_5_alpha_b', 'time_5_alpha_r2', 'time_5_gamma_b', 'time_5_gamma_r2', 'time_5_gamma_logLL', 'time_5_bs', 'time_5_bf', 'time_5_uu0', 'time_5_ul0', 'time_5_su0', 'time_5_sl0', 'time_5_U0', 'time_5_S0', 'time_5_total0', 'time_5_beta_k', 'time_5_gamma_k', 'use_for_dynamics', 'gamma', 'gamma_r2', 'use_for_transition', 'gamma_k', 'gamma_b', 'scHopfield_used', 'sigmoid_threshold', 'sigmoid_exponent', 'sigmoid_offset', 'sigmoid_mse'
uns: 'PCs', 'VecFld_pca', 'VecFld_umap', 'X_umap_neighbors', 'cell_phase_genes', 'cell_type_colors', 'dynamics', 'explained_variance_ratio_', 'feature_selection', 'grid_velocity_pca', 'grid_velocity_umap', 'grid_velocity_umap_ori_perturbation', 'grid_velocity_umap_test', 'jacobian_pca', 'leiden', 'neighbors', 'pca_mean', 'pp', 'response', 'scHopfield'
obsm: 'X', 'X_pca', 'X_pca_SparseVFC', 'X_umap', 'X_umap_SparseVFC', 'X_umap_ori_perturbation', 'X_umap_test', 'acceleration_pca', 'acceleration_umap', 'cell_cycle_scores', 'curvature_pca', 'curvature_umap', 'j_delta_x_perturbation', 'velocity_pca', 'velocity_pca_SparseVFC', 'velocity_umap', 'velocity_umap_SparseVFC', 'velocity_umap_ori_perturbation', 'velocity_umap_test'
layers: 'M_n', 'M_nn', 'M_t', 'M_tn', 'M_tt', 'X_new', 'X_total', 'velocity_alpha_minus_gamma_s', 'sigmoid'
obsp: 'X_umap_connectivities', 'X_umap_distances', 'connectivities', 'cosine_transition_matrix', 'distances', 'fp_transition_rate', 'moments_con', 'pca_ddhodge', 'perturbation_transition_matrix', 'umap_ddhodge'
[5]:
# Visualize sigmoid fits for key genes
genes_to_plot = ['Gata1', 'Klf1', 'Gata2', 'Spi1', 'Cebpa', 'FLI1']
genes_to_plot = [g.upper() for g in genes_to_plot if g.upper() in adata.var_names]
if genes_to_plot:
n_cols = min(3, len(genes_to_plot))
n_rows = (len(genes_to_plot) + n_cols - 1) // n_cols
fig, axes = plt.subplots(n_rows, n_cols, figsize=[5*n_cols, 4*n_rows])
axes = np.atleast_2d(axes).flatten()
for i, gene in enumerate(genes_to_plot):
sch.pl.plot_sigmoid_fit(adata, gene=gene, ax=axes[i],
spliced_key='M_t', show_zeros=False)
# Hide empty axes
for j in range(i+1, len(axes)):
axes[j].axis('off')
plt.tight_layout()
plt.show()
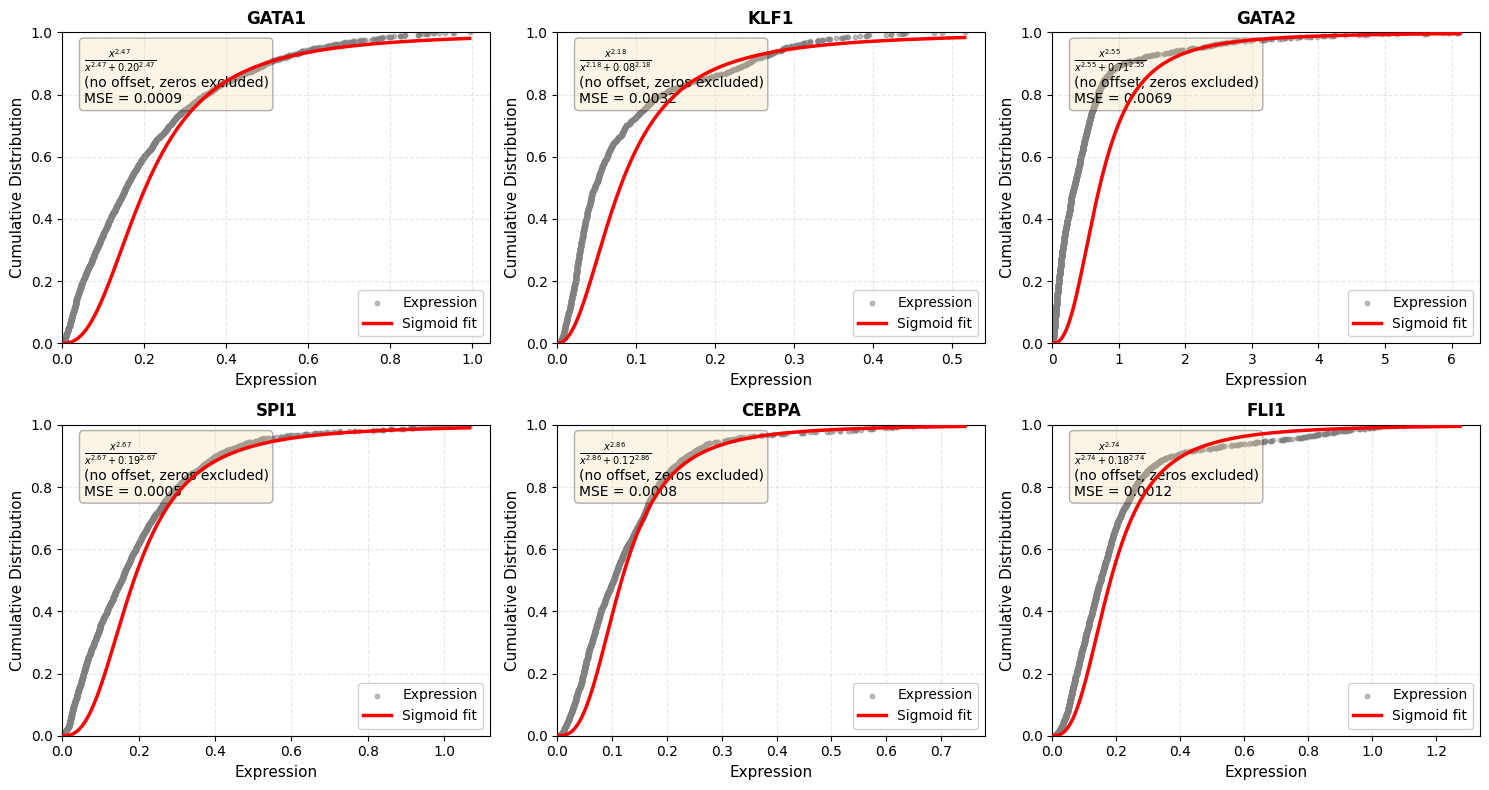
1.5 Network Inference (no scaffold)
Learn the interaction matrix W for each cell cluster by minimizing the
velocity reconstruction error.
[6]:
sch.inf.fit_interactions(
adata,
cluster_key=CLUSTER_KEY,
spliced_key=SPLICED_KEY,
velocity_key=VELOCITY_KEY,
degradation_key=DEGRADATION_KEY,
w_threshold=W_THRESHOLD,
infer_I=True,
refit_gamma=False,
n_epochs=N_EPOCHS,
criterion='MSE',
batch_size=BATCH_SIZE,
use_scheduler=True,
get_plots=False,
device=DEVICE,
)
print("Network inference complete (no scaffold).")
Inferring interaction matrix W and bias vector I for cluster Mon
Inferring interaction matrix W and bias vector I for cluster Meg
Inferring interaction matrix W and bias vector I for cluster MEP-like
Inferring interaction matrix W and bias vector I for cluster Ery
Inferring interaction matrix W and bias vector I for cluster Bas
Inferring interaction matrix W and bias vector I for cluster GMP-like
Inferring interaction matrix W and bias vector I for cluster HSC
Inferring interaction matrix W and bias vector I for cluster Neu
Inferring interaction matrix W and bias vector I for cluster all
Network inference complete (no scaffold).
1.6 Scaffold-Constrained Inference
Load a prior gene regulatory network (GRN) from CellOracle’s mouse scATAC-seq
atlas and use it as a scaffold to regularise the learned W matrix.
[7]:
import celloracle as co
import pandas as pd
print("Loading CellOracle scaffold...")
base_GRN = co.data.load_mouse_scATAC_atlas_base_GRN()
base_GRN.drop(['peak_id'], axis=1, inplace=True)
# Build scaffold matrix (genes × genes; 1 = edge allowed by prior)
scaffold = pd.DataFrame(
0,
index=adata.var.index[genes_to_use],
columns=adata.var.index[genes_to_use]
)
tfs = list(set(base_GRN.columns.str.lower()) & set(scaffold.index.str.lower()))
target_genes = list(
set(base_GRN['gene_short_name'].str.lower().values) & set(scaffold.columns.str.lower())
)
index_map = {gene.lower(): gene for gene in scaffold.index}
col_map = {gene.lower(): gene for gene in scaffold.columns}
for tf in tfs:
tf_original = index_map[tf]
tf_col = [c for c in base_GRN.columns if c.lower() == tf][0]
for target in base_GRN[base_GRN[tf_col] == 1]['gene_short_name']:
if target.lower() in target_genes:
scaffold.loc[tf_original, col_map[target.lower()]] = 1
print(f" Scaffold: {scaffold.sum().sum()} potential connections")
print(f" TFs: {len(tfs)}, Target genes: {len(target_genes)}")
which: no R in (/opt/slurm/puppet/bin:/opt/slurm/cluster/ibex/install-v2/RedHat-9/bin:/opt/slurm/scripts/bin:/usr/lpp/mmfs/bin:/home/bernaljp/miniconda3/envs/SCH/bin:/opt/slurm/puppet/bin:/opt/slurm/cluster/ibex/install-v2/RedHat-9/bin:/opt/slurm/scripts/bin:/usr/lpp/mmfs/bin:/home/bernaljp/miniconda3/condabin:/opt/slurm/puppet/bin:/usr/share/Modules/bin:/opt/slurm/cluster/ibex/install-v2/RedHat-9/bin:/opt/slurm/scripts/bin:/usr/lpp/mmfs/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/opt/slurm/scripts/bin:/opt/puppetlabs/bin:/home/bernaljp/.local/bin:/home/bernaljp/bin:/opt/slurm/scripts/bin:/home/bernaljp/.local/bin:/home/bernaljp/bin:/opt/slurm/scripts/bin:/home/bernaljp/.local/bin:/home/bernaljp/bin)
Loading CellOracle scaffold...
Scaffold: 41693 potential connections
TFs: 73, Target genes: 1148
[8]:
sch.inf.fit_interactions(
adata,
cluster_key=CLUSTER_KEY,
spliced_key=SPLICED_KEY,
velocity_key=VELOCITY_KEY,
degradation_key=DEGRADATION_KEY,
w_threshold=W_THRESHOLD,
w_scaffold=scaffold.values.T,
scaffold_regularization=SCAFFOLD_REGULARIZATION,
only_TFs=True,
infer_I=True,
refit_gamma=False,
n_epochs=N_EPOCHS,
criterion='MSE',
batch_size=BATCH_SIZE,
use_scheduler=True,
get_plots=False,
device=DEVICE,
)
print("Scaffold-constrained network inference complete.")
Inferring interaction matrix W and bias vector I for cluster Mon
/home/bernaljp/packages/scHopfield/scHopfield/inference/optimizer.py:18: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.detach().clone() or sourceTensor.detach().clone().requires_grad_(True), rather than torch.tensor(sourceTensor).
self.register_buffer('mask', torch.tensor(mask, dtype=torch.float32, device=device))
Training Epochs: 1%|▏ | 13/1000 [00:00<00:17, 57.61it/s]
[Epoch 1/1000] Total Loss: 64.630268, Reconstruction Loss: 0.509252, LR: 1.00e-01, Batch size: 128
Training Epochs: 11%|█▏ | 114/1000 [00:01<00:07, 117.88it/s]
[Epoch 101/1000] Total Loss: 10.317851, Reconstruction Loss: 0.008718, LR: 4.00e-02, Batch size: 128
Training Epochs: 22%|██▏ | 218/1000 [00:01<00:06, 121.09it/s]
[Epoch 201/1000] Total Loss: 3.396171, Reconstruction Loss: 0.001726, LR: 1.60e-02, Batch size: 128
Training Epochs: 32%|███▏ | 322/1000 [00:02<00:05, 121.19it/s]
[Epoch 301/1000] Total Loss: 1.288166, Reconstruction Loss: 0.000778, LR: 6.40e-03, Batch size: 128
Training Epochs: 41%|████▏ | 413/1000 [00:03<00:04, 120.04it/s]
[Epoch 401/1000] Total Loss: 0.448385, Reconstruction Loss: 0.000669, LR: 2.56e-03, Batch size: 128
Training Epochs: 52%|█████▏ | 517/1000 [00:04<00:04, 120.24it/s]
[Epoch 501/1000] Total Loss: 0.181946, Reconstruction Loss: 0.000663, LR: 1.02e-03, Batch size: 128
Training Epochs: 62%|██████▏ | 621/1000 [00:05<00:03, 121.60it/s]
[Epoch 601/1000] Total Loss: 0.082942, Reconstruction Loss: 0.000658, LR: 4.10e-04, Batch size: 128
Training Epochs: 72%|███████▎ | 725/1000 [00:06<00:02, 121.45it/s]
[Epoch 701/1000] Total Loss: 0.030161, Reconstruction Loss: 0.000653, LR: 1.64e-04, Batch size: 128
Training Epochs: 82%|████████▏ | 816/1000 [00:06<00:01, 121.36it/s]
[Epoch 801/1000] Total Loss: 0.011939, Reconstruction Loss: 0.000655, LR: 6.55e-05, Batch size: 128
Training Epochs: 92%|█████████▏| 920/1000 [00:07<00:00, 121.64it/s]
[Epoch 901/1000] Total Loss: 0.005090, Reconstruction Loss: 0.000657, LR: 2.62e-05, Batch size: 128
Training Epochs: 100%|██████████| 1000/1000 [00:08<00:00, 118.75it/s]
/home/bernaljp/packages/scHopfield/scHopfield/inference/optimizer.py:18: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.detach().clone() or sourceTensor.detach().clone().requires_grad_(True), rather than torch.tensor(sourceTensor).
self.register_buffer('mask', torch.tensor(mask, dtype=torch.float32, device=device))
[Epoch 1000/1000] Total Loss: 0.002839, Reconstruction Loss: 0.000648, LR: 1.05e-05, Batch size: 128
Inferring interaction matrix W and bias vector I for cluster Meg
Training Epochs: 4%|▎ | 35/1000 [00:00<00:02, 341.73it/s]
[Epoch 1/1000] Total Loss: 73.839462, Reconstruction Loss: 0.418692, LR: 1.00e-01, Batch size: 128
Training Epochs: 14%|█▍ | 142/1000 [00:00<00:02, 350.40it/s]
[Epoch 101/1000] Total Loss: 12.315012, Reconstruction Loss: 0.022208, LR: 4.00e-02, Batch size: 128
Training Epochs: 25%|██▌ | 250/1000 [00:00<00:02, 351.62it/s]
[Epoch 201/1000] Total Loss: 3.871475, Reconstruction Loss: 0.002862, LR: 1.60e-02, Batch size: 128
Training Epochs: 36%|███▌ | 358/1000 [00:01<00:01, 350.26it/s]
[Epoch 301/1000] Total Loss: 1.582910, Reconstruction Loss: 0.001613, LR: 6.40e-03, Batch size: 128
Training Epochs: 47%|████▋ | 466/1000 [00:01<00:01, 350.94it/s]
[Epoch 401/1000] Total Loss: 0.629308, Reconstruction Loss: 0.001433, LR: 2.56e-03, Batch size: 128
Training Epochs: 54%|█████▍ | 538/1000 [00:01<00:01, 349.74it/s]
[Epoch 501/1000] Total Loss: 0.266602, Reconstruction Loss: 0.001431, LR: 1.02e-03, Batch size: 128
Training Epochs: 64%|██████▍ | 644/1000 [00:01<00:01, 350.63it/s]
[Epoch 601/1000] Total Loss: 0.107586, Reconstruction Loss: 0.001420, LR: 4.10e-04, Batch size: 128
Training Epochs: 75%|███████▌ | 751/1000 [00:02<00:00, 349.75it/s]
[Epoch 701/1000] Total Loss: 0.044884, Reconstruction Loss: 0.001442, LR: 1.64e-04, Batch size: 128
Training Epochs: 86%|████████▌ | 859/1000 [00:02<00:00, 349.57it/s]
[Epoch 801/1000] Total Loss: 0.019176, Reconstruction Loss: 0.001432, LR: 6.55e-05, Batch size: 128
Training Epochs: 96%|█████████▋| 965/1000 [00:02<00:00, 349.67it/s]
[Epoch 901/1000] Total Loss: 0.008195, Reconstruction Loss: 0.001432, LR: 2.62e-05, Batch size: 128
Training Epochs: 100%|██████████| 1000/1000 [00:02<00:00, 349.73it/s]
[Epoch 1000/1000] Total Loss: 0.004075, Reconstruction Loss: 0.001431, LR: 1.05e-05, Batch size: 128
Inferring interaction matrix W and bias vector I for cluster MEP-like
Training Epochs: 1%| | 12/1000 [00:00<00:08, 115.12it/s]
[Epoch 1/1000] Total Loss: 64.425922, Reconstruction Loss: 0.457732, LR: 1.00e-01, Batch size: 128
Training Epochs: 12%|█▏ | 115/1000 [00:00<00:07, 121.61it/s]
[Epoch 101/1000] Total Loss: 10.250659, Reconstruction Loss: 0.006966, LR: 4.00e-02, Batch size: 128
Training Epochs: 22%|██▏ | 219/1000 [00:01<00:06, 120.06it/s]
[Epoch 201/1000] Total Loss: 3.441626, Reconstruction Loss: 0.001272, LR: 1.60e-02, Batch size: 128
Training Epochs: 32%|███▏ | 323/1000 [00:02<00:05, 120.57it/s]
[Epoch 301/1000] Total Loss: 1.277202, Reconstruction Loss: 0.000542, LR: 6.40e-03, Batch size: 128
Training Epochs: 41%|████▏ | 414/1000 [00:03<00:04, 121.17it/s]
[Epoch 401/1000] Total Loss: 0.453951, Reconstruction Loss: 0.000449, LR: 2.56e-03, Batch size: 128
Training Epochs: 52%|█████▏ | 518/1000 [00:04<00:04, 120.23it/s]
[Epoch 501/1000] Total Loss: 0.179148, Reconstruction Loss: 0.000451, LR: 1.02e-03, Batch size: 128
Training Epochs: 62%|██████▏ | 622/1000 [00:05<00:03, 120.11it/s]
[Epoch 601/1000] Total Loss: 0.082500, Reconstruction Loss: 0.000452, LR: 4.10e-04, Batch size: 128
Training Epochs: 72%|███████▏ | 721/1000 [00:05<00:02, 119.60it/s]
[Epoch 701/1000] Total Loss: 0.030633, Reconstruction Loss: 0.000443, LR: 1.64e-04, Batch size: 128
Training Epochs: 82%|████████▏ | 824/1000 [00:06<00:01, 119.85it/s]
[Epoch 801/1000] Total Loss: 0.011891, Reconstruction Loss: 0.000443, LR: 6.55e-05, Batch size: 128
Training Epochs: 92%|█████████▏| 920/1000 [00:07<00:00, 118.74it/s]
[Epoch 901/1000] Total Loss: 0.004998, Reconstruction Loss: 0.000449, LR: 2.62e-05, Batch size: 128
Training Epochs: 100%|██████████| 1000/1000 [00:08<00:00, 120.02it/s]
[Epoch 1000/1000] Total Loss: 0.002539, Reconstruction Loss: 0.000437, LR: 1.05e-05, Batch size: 128
Inferring interaction matrix W and bias vector I for cluster Ery
Training Epochs: 3%|▎ | 34/1000 [00:00<00:02, 332.50it/s]
[Epoch 1/1000] Total Loss: 73.817230, Reconstruction Loss: 0.397020, LR: 1.00e-01, Batch size: 128
Training Epochs: 14%|█▍ | 139/1000 [00:00<00:02, 343.05it/s]
[Epoch 101/1000] Total Loss: 12.342674, Reconstruction Loss: 0.016045, LR: 4.00e-02, Batch size: 128
Training Epochs: 24%|██▍ | 244/1000 [00:00<00:02, 342.50it/s]
[Epoch 201/1000] Total Loss: 3.884972, Reconstruction Loss: 0.001988, LR: 1.60e-02, Batch size: 128
Training Epochs: 35%|███▍ | 349/1000 [00:01<00:01, 344.04it/s]
[Epoch 301/1000] Total Loss: 1.576656, Reconstruction Loss: 0.001246, LR: 6.40e-03, Batch size: 128
Training Epochs: 45%|████▌ | 454/1000 [00:01<00:01, 344.45it/s]
[Epoch 401/1000] Total Loss: 0.628460, Reconstruction Loss: 0.001144, LR: 2.56e-03, Batch size: 128
Training Epochs: 56%|█████▌ | 559/1000 [00:01<00:01, 345.28it/s]
[Epoch 501/1000] Total Loss: 0.265586, Reconstruction Loss: 0.001133, LR: 1.02e-03, Batch size: 128
Training Epochs: 66%|██████▋ | 664/1000 [00:01<00:00, 345.31it/s]
[Epoch 601/1000] Total Loss: 0.106788, Reconstruction Loss: 0.001082, LR: 4.10e-04, Batch size: 128
Training Epochs: 77%|███████▋ | 769/1000 [00:02<00:00, 345.70it/s]
[Epoch 701/1000] Total Loss: 0.043843, Reconstruction Loss: 0.001136, LR: 1.64e-04, Batch size: 128
Training Epochs: 84%|████████▍ | 839/1000 [00:02<00:00, 344.89it/s]
[Epoch 801/1000] Total Loss: 0.018806, Reconstruction Loss: 0.001135, LR: 6.55e-05, Batch size: 128
Training Epochs: 94%|█████████▍| 944/1000 [00:02<00:00, 345.13it/s]
[Epoch 901/1000] Total Loss: 0.007990, Reconstruction Loss: 0.001082, LR: 2.62e-05, Batch size: 128
Training Epochs: 100%|██████████| 1000/1000 [00:02<00:00, 344.10it/s]
[Epoch 1000/1000] Total Loss: 0.003727, Reconstruction Loss: 0.001065, LR: 1.05e-05, Batch size: 128
Inferring interaction matrix W and bias vector I for cluster Bas
Training Epochs: 3%|▎ | 34/1000 [00:00<00:02, 338.89it/s]
[Epoch 1/1000] Total Loss: 74.011673, Reconstruction Loss: 0.420055, LR: 1.00e-01, Batch size: 128
Training Epochs: 14%|█▍ | 140/1000 [00:00<00:02, 347.34it/s]
[Epoch 101/1000] Total Loss: 12.369323, Reconstruction Loss: 0.018950, LR: 4.00e-02, Batch size: 128
Training Epochs: 25%|██▍ | 246/1000 [00:00<00:02, 348.14it/s]
[Epoch 201/1000] Total Loss: 3.888886, Reconstruction Loss: 0.002169, LR: 1.60e-02, Batch size: 128
Training Epochs: 35%|███▌ | 351/1000 [00:01<00:01, 346.70it/s]
[Epoch 301/1000] Total Loss: 1.600862, Reconstruction Loss: 0.001095, LR: 6.40e-03, Batch size: 128
Training Epochs: 46%|████▌ | 457/1000 [00:01<00:01, 347.96it/s]
[Epoch 401/1000] Total Loss: 0.632268, Reconstruction Loss: 0.000978, LR: 2.56e-03, Batch size: 128
Training Epochs: 56%|█████▌ | 562/1000 [00:01<00:01, 347.75it/s]
[Epoch 501/1000] Total Loss: 0.264172, Reconstruction Loss: 0.000935, LR: 1.02e-03, Batch size: 128
Training Epochs: 67%|██████▋ | 669/1000 [00:01<00:00, 348.48it/s]
[Epoch 601/1000] Total Loss: 0.106983, Reconstruction Loss: 0.000956, LR: 4.10e-04, Batch size: 128
Training Epochs: 74%|███████▍ | 740/1000 [00:02<00:00, 348.17it/s]
[Epoch 701/1000] Total Loss: 0.044257, Reconstruction Loss: 0.000955, LR: 1.64e-04, Batch size: 128
Training Epochs: 85%|████████▍ | 846/1000 [00:02<00:00, 348.44it/s]
[Epoch 801/1000] Total Loss: 0.018226, Reconstruction Loss: 0.000959, LR: 6.55e-05, Batch size: 128
Training Epochs: 95%|█████████▌| 953/1000 [00:02<00:00, 348.59it/s]
[Epoch 901/1000] Total Loss: 0.007662, Reconstruction Loss: 0.000973, LR: 2.62e-05, Batch size: 128
Training Epochs: 100%|██████████| 1000/1000 [00:02<00:00, 347.40it/s]
[Epoch 1000/1000] Total Loss: 0.003573, Reconstruction Loss: 0.000967, LR: 1.05e-05, Batch size: 128
Inferring interaction matrix W and bias vector I for cluster GMP-like
Training Epochs: 4%|▎ | 35/1000 [00:00<00:02, 341.57it/s]
[Epoch 1/1000] Total Loss: 73.960991, Reconstruction Loss: 0.378584, LR: 1.00e-01, Batch size: 128
Training Epochs: 14%|█▍ | 142/1000 [00:00<00:02, 349.31it/s]
[Epoch 101/1000] Total Loss: 12.395257, Reconstruction Loss: 0.011156, LR: 4.00e-02, Batch size: 128
Training Epochs: 25%|██▌ | 250/1000 [00:00<00:02, 349.98it/s]
[Epoch 201/1000] Total Loss: 3.846868, Reconstruction Loss: 0.001018, LR: 1.60e-02, Batch size: 128
Training Epochs: 36%|███▌ | 358/1000 [00:01<00:01, 349.96it/s]
[Epoch 301/1000] Total Loss: 1.566379, Reconstruction Loss: 0.000362, LR: 6.40e-03, Batch size: 128
Training Epochs: 47%|████▋ | 466/1000 [00:01<00:01, 350.61it/s]
[Epoch 401/1000] Total Loss: 0.630207, Reconstruction Loss: 0.000301, LR: 2.56e-03, Batch size: 128
Training Epochs: 54%|█████▍ | 538/1000 [00:01<00:01, 350.82it/s]
[Epoch 501/1000] Total Loss: 0.263469, Reconstruction Loss: 0.000286, LR: 1.02e-03, Batch size: 128
Training Epochs: 65%|██████▍ | 646/1000 [00:01<00:01, 350.29it/s]
[Epoch 601/1000] Total Loss: 0.106407, Reconstruction Loss: 0.000286, LR: 4.10e-04, Batch size: 128
Training Epochs: 75%|███████▌ | 754/1000 [00:02<00:00, 350.60it/s]
[Epoch 701/1000] Total Loss: 0.043902, Reconstruction Loss: 0.000291, LR: 1.64e-04, Batch size: 128
Training Epochs: 86%|████████▌ | 862/1000 [00:02<00:00, 350.23it/s]
[Epoch 801/1000] Total Loss: 0.017809, Reconstruction Loss: 0.000289, LR: 6.55e-05, Batch size: 128
Training Epochs: 97%|█████████▋| 970/1000 [00:02<00:00, 350.66it/s]
[Epoch 901/1000] Total Loss: 0.007113, Reconstruction Loss: 0.000297, LR: 2.62e-05, Batch size: 128
Training Epochs: 100%|██████████| 1000/1000 [00:02<00:00, 349.80it/s]
[Epoch 1000/1000] Total Loss: 0.002894, Reconstruction Loss: 0.000289, LR: 1.05e-05, Batch size: 128
Inferring interaction matrix W and bias vector I for cluster HSC
Training Epochs: 2%|▏ | 18/1000 [00:00<00:05, 173.32it/s]
[Epoch 1/1000] Total Loss: 66.329967, Reconstruction Loss: 0.507938, LR: 1.00e-01, Batch size: 128
Training Epochs: 13%|█▎ | 126/1000 [00:00<00:04, 177.87it/s]
[Epoch 101/1000] Total Loss: 10.176931, Reconstruction Loss: 0.009899, LR: 4.00e-02, Batch size: 128
Training Epochs: 23%|██▎ | 234/1000 [00:01<00:04, 177.97it/s]
[Epoch 201/1000] Total Loss: 4.540389, Reconstruction Loss: 0.001357, LR: 1.60e-02, Batch size: 128
Training Epochs: 32%|███▏ | 324/1000 [00:01<00:03, 178.25it/s]
[Epoch 301/1000] Total Loss: 1.749087, Reconstruction Loss: 0.000375, LR: 6.40e-03, Batch size: 128
Training Epochs: 43%|████▎ | 432/1000 [00:02<00:03, 178.21it/s]
[Epoch 401/1000] Total Loss: 0.573783, Reconstruction Loss: 0.000285, LR: 2.56e-03, Batch size: 128
Training Epochs: 52%|█████▏ | 522/1000 [00:02<00:02, 178.20it/s]
[Epoch 501/1000] Total Loss: 0.243815, Reconstruction Loss: 0.000278, LR: 1.02e-03, Batch size: 128
Training Epochs: 63%|██████▎ | 630/1000 [00:03<00:02, 177.69it/s]
[Epoch 601/1000] Total Loss: 0.095035, Reconstruction Loss: 0.000280, LR: 4.10e-04, Batch size: 128
Training Epochs: 72%|███████▏ | 720/1000 [00:04<00:01, 177.78it/s]
[Epoch 701/1000] Total Loss: 0.042646, Reconstruction Loss: 0.000282, LR: 1.64e-04, Batch size: 128
Training Epochs: 83%|████████▎ | 828/1000 [00:04<00:00, 178.19it/s]
[Epoch 801/1000] Total Loss: 0.015770, Reconstruction Loss: 0.000280, LR: 6.55e-05, Batch size: 128
Training Epochs: 94%|█████████▎| 936/1000 [00:05<00:00, 178.32it/s]
[Epoch 901/1000] Total Loss: 0.006564, Reconstruction Loss: 0.000278, LR: 2.62e-05, Batch size: 128
Training Epochs: 100%|██████████| 1000/1000 [00:05<00:00, 178.11it/s]
[Epoch 1000/1000] Total Loss: 0.002728, Reconstruction Loss: 0.000277, LR: 1.05e-05, Batch size: 128
Inferring interaction matrix W and bias vector I for cluster Neu
Training Epochs: 4%|▍ | 43/1000 [00:00<00:02, 428.66it/s]
[Epoch 1/1000] Total Loss: 74.491829, Reconstruction Loss: 0.433057, LR: 1.00e-01, Batch size: 32
Training Epochs: 19%|█▊ | 186/1000 [00:00<00:01, 466.45it/s]
[Epoch 101/1000] Total Loss: 12.266115, Reconstruction Loss: 0.028103, LR: 4.00e-02, Batch size: 32
Training Epochs: 28%|██▊ | 281/1000 [00:00<00:01, 470.28it/s]
[Epoch 201/1000] Total Loss: 3.847661, Reconstruction Loss: 0.003100, LR: 1.60e-02, Batch size: 32
Training Epochs: 38%|███▊ | 377/1000 [00:00<00:01, 471.26it/s]
[Epoch 301/1000] Total Loss: 1.536790, Reconstruction Loss: 0.001474, LR: 6.40e-03, Batch size: 32
Training Epochs: 47%|████▋ | 473/1000 [00:01<00:01, 472.79it/s]
[Epoch 401/1000] Total Loss: 0.621251, Reconstruction Loss: 0.001264, LR: 2.56e-03, Batch size: 32
Training Epochs: 57%|█████▋ | 569/1000 [00:01<00:00, 473.19it/s]
[Epoch 501/1000] Total Loss: 0.274787, Reconstruction Loss: 0.001268, LR: 1.02e-03, Batch size: 32
Training Epochs: 66%|██████▋ | 665/1000 [00:01<00:00, 472.87it/s]
[Epoch 601/1000] Total Loss: 0.107496, Reconstruction Loss: 0.001261, LR: 4.10e-04, Batch size: 32
Training Epochs: 76%|███████▌ | 761/1000 [00:01<00:00, 472.61it/s]
[Epoch 701/1000] Total Loss: 0.045860, Reconstruction Loss: 0.001261, LR: 1.64e-04, Batch size: 32
Training Epochs: 86%|████████▌ | 857/1000 [00:01<00:00, 472.97it/s]
[Epoch 801/1000] Total Loss: 0.019908, Reconstruction Loss: 0.001261, LR: 6.55e-05, Batch size: 32
Training Epochs: 95%|█████████▌| 953/1000 [00:02<00:00, 472.33it/s]
[Epoch 901/1000] Total Loss: 0.007731, Reconstruction Loss: 0.001261, LR: 2.62e-05, Batch size: 32
Training Epochs: 100%|██████████| 1000/1000 [00:02<00:00, 470.02it/s]
[Epoch 1000/1000] Total Loss: 0.003867, Reconstruction Loss: 0.001261, LR: 1.05e-05, Batch size: 32
Inferring interaction matrix W and bias vector I for cluster all
Training Epochs: 0%| | 3/1000 [00:00<00:42, 23.74it/s]
[Epoch 1/1000] Total Loss: 37.163322, Reconstruction Loss: 0.238663, LR: 1.00e-01, Batch size: 128
Training Epochs: 10%|█ | 105/1000 [00:04<00:36, 24.37it/s]
[Epoch 101/1000] Total Loss: 7.501845, Reconstruction Loss: 0.004914, LR: 4.00e-02, Batch size: 128
Training Epochs: 20%|██ | 204/1000 [00:08<00:32, 24.33it/s]
[Epoch 201/1000] Total Loss: 2.499651, Reconstruction Loss: 0.001558, LR: 1.60e-02, Batch size: 128
Training Epochs: 30%|███ | 303/1000 [00:12<00:28, 24.32it/s]
[Epoch 301/1000] Total Loss: 0.952395, Reconstruction Loss: 0.000967, LR: 6.40e-03, Batch size: 128
Training Epochs: 40%|████ | 405/1000 [00:16<00:24, 24.48it/s]
[Epoch 401/1000] Total Loss: 0.367137, Reconstruction Loss: 0.000861, LR: 2.56e-03, Batch size: 128
Training Epochs: 50%|█████ | 504/1000 [00:20<00:20, 24.46it/s]
[Epoch 501/1000] Total Loss: 0.145286, Reconstruction Loss: 0.000847, LR: 1.02e-03, Batch size: 128
Training Epochs: 60%|██████ | 603/1000 [00:24<00:16, 24.39it/s]
[Epoch 601/1000] Total Loss: 0.060421, Reconstruction Loss: 0.000840, LR: 4.10e-04, Batch size: 128
Training Epochs: 70%|███████ | 705/1000 [00:28<00:12, 24.45it/s]
[Epoch 701/1000] Total Loss: 0.025516, Reconstruction Loss: 0.000842, LR: 1.64e-04, Batch size: 128
Training Epochs: 80%|████████ | 804/1000 [00:32<00:08, 24.48it/s]
[Epoch 801/1000] Total Loss: 0.010301, Reconstruction Loss: 0.000835, LR: 6.55e-05, Batch size: 128
Training Epochs: 90%|█████████ | 903/1000 [00:36<00:03, 24.44it/s]
[Epoch 901/1000] Total Loss: 0.004753, Reconstruction Loss: 0.000836, LR: 2.62e-05, Batch size: 128
Training Epochs: 100%|██████████| 1000/1000 [00:40<00:00, 24.49it/s]
[Epoch 1000/1000] Total Loss: 0.003123, Reconstruction Loss: 0.000836, LR: 1.05e-05, Batch size: 128
Scaffold-constrained network inference complete.
1.7 Save / Load Model
Models can be serialised to an HDF5 file for later use. This is especially
useful for large datasets where re-inference is expensive.
[9]:
# Save the fitted model
MODEL_FILE = 'model.h5sch'
sch.tl.save_model(adata, MODEL_FILE, overwrite=True)
print(f"Model saved to '{MODEL_FILE}'")
Model saved to 'model.h5sch' | clusters=['Bas', 'Ery', 'GMP-like', 'HSC', 'MEP-like', 'Meg', 'Mon', 'Neu', 'all'] | genes=1728
Model saved to 'model.h5sch'
[10]:
# Load the model back into a fresh AnnData object.
# If adata_loaded has more genes than the saved model (e.g. the full dataset
# before NaN filtering), load_model subsets it in-place to the model gene set.
adata_loaded = sc.read_h5ad(DATA_PATH + DATASET_FILE)
adata_loaded = sch.tl.load_model(adata_loaded, MODEL_FILE)
print("Model loaded successfully.")
print(adata_loaded)
Model loaded from 'model.h5sch' | clusters=['Bas', 'Ery', 'GMP-like', 'HSC', 'MEP-like', 'Meg', 'Mon', 'Neu', 'all'] | genes=1728
Model loaded successfully.
AnnData object with n_obs × n_vars = 1947 × 1728
obs: 'batch', 'time', 'cell_type', 'nGenes', 'nCounts', 'pMito', 'pass_basic_filter', 'new_Size_Factor', 'initial_new_cell_size', 'total_Size_Factor', 'initial_total_cell_size', 'spliced_Size_Factor', 'initial_spliced_cell_size', 'unspliced_Size_Factor', 'initial_unspliced_cell_size', 'Size_Factor', 'initial_cell_size', 'ntr', 'cell_cycle_phase', 'leiden', 'control_point_pca', 'inlier_prob_pca', 'obs_vf_angle_pca', 'pca_ddhodge_div', 'pca_ddhodge_potential', 'acceleration_pca', 'curvature_pca', 'n_counts', 'mt_frac', 'jacobian_det_pca', 'manual_selection', 'divergence_pca', 'curv_leiden', 'curv_louvain', 'SPI1->GATA1_jacobian', 'jacobian', 'umap_ori_leiden', 'umap_ori_louvain', 'umap_ddhodge_div', 'umap_ddhodge_potential', 'curl_umap', 'divergence_umap', 'acceleration_umap', 'control_point_umap_ori', 'inlier_prob_umap_ori', 'obs_vf_angle_umap_ori', 'curvature_umap_ori'
var: 'gene_name', 'gene_id', 'nCells', 'nCounts', 'pass_basic_filter', 'use_for_pca', 'frac', 'ntr', 'time_3_alpha', 'time_3_beta', 'time_3_gamma', 'time_3_half_life', 'time_3_alpha_b', 'time_3_alpha_r2', 'time_3_gamma_b', 'time_3_gamma_r2', 'time_3_gamma_logLL', 'time_3_delta_b', 'time_3_delta_r2', 'time_3_bs', 'time_3_bf', 'time_3_uu0', 'time_3_ul0', 'time_3_su0', 'time_3_sl0', 'time_3_U0', 'time_3_S0', 'time_3_total0', 'time_3_beta_k', 'time_3_gamma_k', 'time_5_alpha', 'time_5_beta', 'time_5_gamma', 'time_5_half_life', 'time_5_alpha_b', 'time_5_alpha_r2', 'time_5_gamma_b', 'time_5_gamma_r2', 'time_5_gamma_logLL', 'time_5_bs', 'time_5_bf', 'time_5_uu0', 'time_5_ul0', 'time_5_su0', 'time_5_sl0', 'time_5_U0', 'time_5_S0', 'time_5_total0', 'time_5_beta_k', 'time_5_gamma_k', 'use_for_dynamics', 'gamma', 'gamma_r2', 'use_for_transition', 'gamma_k', 'gamma_b', 'I_Bas', 'I_Ery', 'I_GMP-like', 'I_HSC', 'I_MEP-like', 'I_Meg', 'I_Mon', 'I_Neu', 'I_all', 'scHopfield_used', 'sigmoid_exponent', 'sigmoid_mse', 'sigmoid_offset', 'sigmoid_threshold'
uns: 'PCs', 'VecFld_pca', 'VecFld_umap', 'X_umap_neighbors', 'cell_phase_genes', 'cell_type_colors', 'dynamics', 'explained_variance_ratio_', 'feature_selection', 'grid_velocity_pca', 'grid_velocity_umap', 'grid_velocity_umap_ori_perturbation', 'grid_velocity_umap_test', 'jacobian_pca', 'leiden', 'neighbors', 'pca_mean', 'pp', 'response', 'scHopfield'
obsm: 'X', 'X_pca', 'X_pca_SparseVFC', 'X_umap', 'X_umap_SparseVFC', 'X_umap_ori_perturbation', 'X_umap_test', 'acceleration_pca', 'acceleration_umap', 'cell_cycle_scores', 'curvature_pca', 'curvature_umap', 'j_delta_x_perturbation', 'velocity_pca', 'velocity_pca_SparseVFC', 'velocity_umap', 'velocity_umap_SparseVFC', 'velocity_umap_ori_perturbation', 'velocity_umap_test'
layers: 'M_n', 'M_nn', 'M_t', 'M_tn', 'M_tt', 'X_new', 'X_total', 'velocity_alpha_minus_gamma_s'
obsp: 'X_umap_connectivities', 'X_umap_distances', 'connectivities', 'cosine_transition_matrix', 'distances', 'fp_transition_rate', 'moments_con', 'pca_ddhodge', 'perturbation_transition_matrix', 'umap_ddhodge'
varp: 'W_Bas', 'W_Ery', 'W_GMP-like', 'W_HSC', 'W_MEP-like', 'W_Meg', 'W_Mon', 'W_Neu', 'W_all'